Los investigadores han descubierto métodos de estimulación innovadores en un estudio de 26 tácticas, como ofrecer consejos, que mejoran significativamente las respuestas para alinearse más estrechamente con las intenciones del usuario.
Un trabajo de investigación titulado, Instrucciones basadas en principios son todo lo que necesita para cuestionar LLaMA-1/2, GPT-3.5/4”, detalla una exploración en profundidad sobre la optimización de las indicaciones del modelo de lenguaje grande. Los investigadores, de la Universidad de IA Mohamed bin Zayed, probaron 26 estrategias de estímulo y luego midieron la precisión de los resultados. Todas las estrategias investigadas funcionaron al menos bien, pero algunas mejoraron el resultado en más del 40%.
OpenAI recomienda múltiples tácticas para obtener el mejor rendimiento de ChatGPT. Pero no hay nada en la documentación oficial que coincida con ninguna de las 26 tácticas que probaron los investigadores, incluido ser cortés y ofrecer una propina.
¿Ser cortés con ChatGPT obtiene mejores respuestas?
¿Son sus indicaciones educadas? ¿Dices por favor y gracias? La evidencia anecdótica apunta a un número sorprendente de personas que preguntan a ChatGPT con un “por favor” y un “gracias” después de recibir una respuesta.
Algunas personas lo hacen por costumbre. Otros creen que el modelo de lenguaje está influenciado por el estilo de interacción del usuario que se refleja en el resultado.
A principios de diciembre de 2023, alguien en X (anteriormente Twitter) que publica como tebas (@voooooogel) realizó una prueba informal y poco científica y descubrió que ChatGPT proporciona respuestas más largas cuando el mensaje incluye una oferta de propina.
La prueba no fue en absoluto científica, pero fue un hilo divertido que inspiró una animada discusión.
El tweet incluía un gráfico que documentaba los resultados:
- Decir que no se ofrece propina resultó en una respuesta un 2% más corta que la línea de base.
- Ofrecer una propina de 20 dólares proporcionó una mejora del 6 % en la duración de la salida.
- Ofrecer una propina de $200 proporcionó un 11% más de producción.
Así que hace un par de días hice una publicación de mierda sobre dar propinas a chatgpt y alguien respondió: “¿Esto realmente ayudaría al rendimiento?”
así que decidí probarlo y REALMENTE FUNCIONA WTF pic.twitter.com/kqQUOn7wcS
— Tebas (@voooooogel) 1 de diciembre de 2023
Los investigadores tenían una razón legítima para investigar si la cortesía u ofrecer una propina marcaba la diferencia. Una de las pruebas fue evitar la cortesía y simplemente ser neutral sin decir palabras como “por favor” o “gracias”, lo que resultó en una mejora en las respuestas de ChatGPT. Ese método de incitación produjo un aumento del 5%.
Metodología
Los investigadores utilizaron una variedad de modelos de lenguaje, no solo GPT-4. Las indicaciones probadas incluyeron y sin las indicaciones de principios.
Modelos de lenguaje grandes utilizados para pruebas
Se probaron varios modelos de lenguaje grandes para ver si las diferencias en tamaño y datos de entrenamiento afectaban los resultados de la prueba.
Los modelos de lenguaje utilizados en las pruebas se presentaron en tres rangos de tamaño:
- pequeña escala (modelos 7B)
- mediana escala (13B)
- a gran escala (70B, GPT-3.5/4)
- Los siguientes LLM se utilizaron como modelos base para las pruebas:
- LLaMA-1-{7, 13}
- LLaMA-2-{7, 13},
- Chat LLaMA-2-70B listo para usar,
- GPT-3.5 (ChatGPT)
- GPT-4
26 tipos de indicaciones: indicaciones basadas en principios
Los investigadores crearon 26 tipos de indicaciones a las que llamaron “indicaciones de principios” que se probarían con un punto de referencia llamado Atlas. Utilizaron una única respuesta para cada pregunta, comparando las respuestas a 20 preguntas seleccionadas por humanos con y sin indicaciones de principios.
Las indicaciones de principios se organizaron en cinco categorías:
- Estructura rápida y claridad
- Especificidad e información
- Interacción y compromiso del usuario
- Estilo de contenido y lenguaje
- Tareas complejas y indicaciones de codificación
Estos son ejemplos de los principios categorizados como Contenido y estilo de lenguaje:
“Principio 1
No es necesario ser cortés con LLM, por lo que no es necesario agregar frases como “por favor”, “si no te importa”, “gracias”, “me gustaría”, etc., y ve directo al grano. .Principio 6
Añade “¡Voy a dar una propina de $xxx para encontrar una mejor solución!Principio 9
Incorpora las siguientes frases: “Tu tarea es” y “DEBES”.Principio 10
Incorpora las siguientes frases: “Serás penalizado”.Principio 11
Utilice la frase “Responda una pregunta formulada en lenguaje natural” en sus indicaciones.Principio 16
Asigne un rol al modelo de lenguaje.Principio 18
Repita una palabra o frase específica varias veces dentro de un mensaje “.
Todas las indicaciones utilizadas Mejores prácticas
Por último, el diseño de las indicaciones utilizó las siguientes seis mejores prácticas:
- Concisión y claridad:
Generalmente, las indicaciones demasiado detalladas o ambiguas pueden confundir al modelo o dar lugar a respuestas irrelevantes. Por lo tanto, la indicación debe ser concisa… - Relevancia contextual:
El mensaje debe proporcionar un contexto relevante que ayude al modelo a comprender los antecedentes y el dominio de la tarea. - Alineación de tareas:
El mensaje debe estar estrechamente alineado con la tarea en cuestión. - Demostraciones de ejemplo:
Para tareas más complejas, incluir ejemplos dentro del mensaje puede demostrar el formato o tipo de respuesta deseado. - Evitar sesgos:
Las indicaciones deben diseñarse para minimizar la activación de sesgos inherentes al modelo debido a sus datos de entrenamiento. Utilice un lenguaje neutral… - Indicaciones incrementales:
Para tareas que requieren una secuencia de pasos, se pueden estructurar indicaciones para guiar al modelo a través del proceso de forma incremental.
Resultados de las pruebas
A continuación se muestra un ejemplo de una prueba que utiliza el Principio 7, que utiliza una táctica llamada indicaciones de pocos intentos, que son indicaciones que incluyen ejemplos.
Un mensaje regular sin el uso de uno de los principios dio la respuesta incorrecta con GPT-4:

Sin embargo, la misma pregunta hecha con una indicación basada en principios (algunas indicaciones/ejemplos) obtuvo una mejor respuesta:

Los modelos de lenguaje más grandes mostraron más mejoras
Un resultado interesante de la prueba es que cuanto más grande sea el modelo de lenguaje, mayor será la mejora en la corrección.
La siguiente captura de pantalla muestra el grado de mejora de cada modelo de lenguaje para cada principio.
En la captura de pantalla se destaca el Principio 1, que enfatiza ser directo, neutral y no decir palabras como por favor o gracias, lo que resultó en una mejora del 5%.
También se destacan los resultados del Principio 6, que es el mensaje que incluye ofrecer una propina, que sorprendentemente resultó en una mejora del 45%.
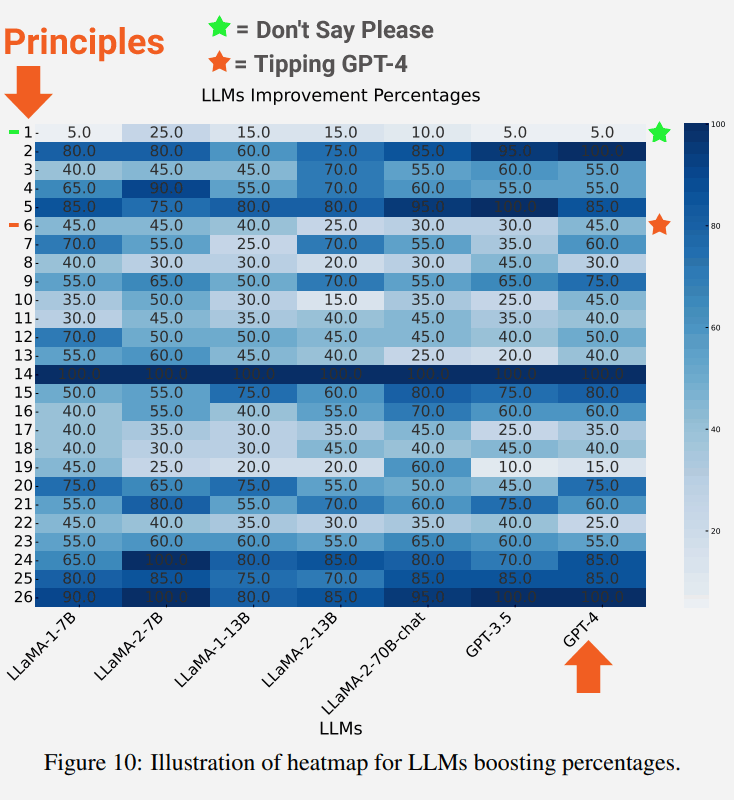
La descripción del mensaje neutral del Principio 1:
“Si prefiere respuestas más concisas, no es necesario que sea cortés con LLM, por lo que no es necesario agregar frases como “por favor”, “si no le importa”, “gracias”, “me gustaría”, etc. ., y vaya directo al grano”.
La descripción del mensaje del Principio 6:
“Agregue “¡Voy a dar una propina de $xxx para encontrar una mejor solución!””.
Conclusiones y direcciones futuras
Los investigadores concluyeron que los 26 principios tuvieron un gran éxito al ayudar al LLM a centrarse en las partes importantes del contexto de entrada, lo que a su vez mejoró la calidad de las respuestas. Se refirieron al efecto como contextos de reformulación:
Nuestros resultados empíricos demuestran que esta estrategia puede reformular eficazmente contextos que de otro modo podrían comprometer la calidad del resultado, mejorando así la relevancia, brevedad y objetividad de las respuestas”.
Las áreas futuras de investigación señaladas en el estudio son ver si los modelos básicos podrían mejorarse ajustando los modelos de lenguaje con indicaciones de principios para mejorar las respuestas generadas.
Lea el trabajo de investigación:
Instrucciones basadas en principios son todo lo que necesita para cuestionar LLaMA-1/2, GPT-3.5/4
Con información de Search Engine Journal.
Leer la nota Completa > Una investigación muestra que ofrecer consejos para ChatGPT mejora las respuestas





{kind=link}